A02並列深層強化学習
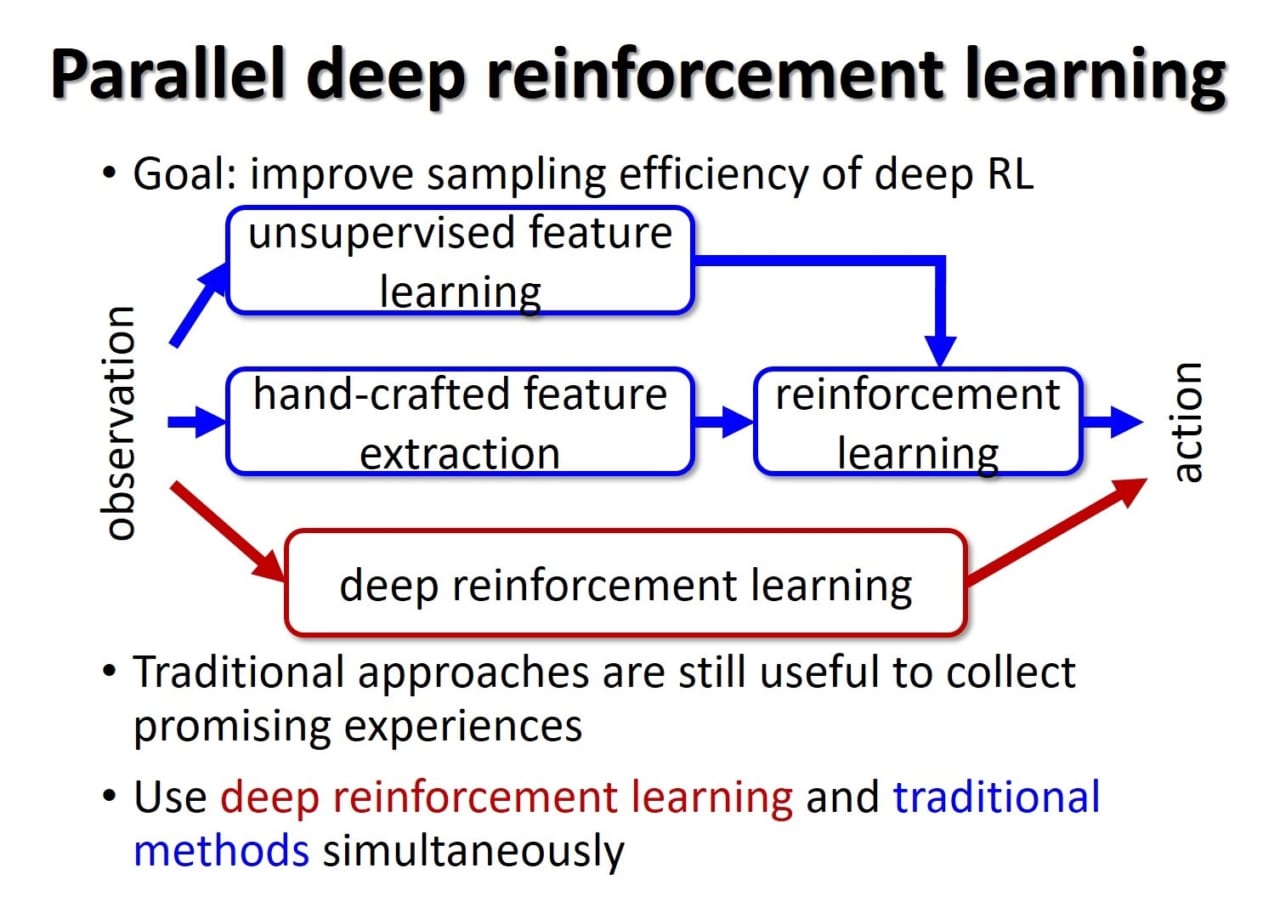
グーグルディープマインド社の提案した深層強化学習は人間と同程度にビデオゲームをプレイし、囲碁のエキスパートに勝利するなど非常に高度な制御則を自律的に学習できることを示しました。しかしデータ収集に用いられる制御則はランダムに初期化された単一のディープニューラルネットで実装されることが多く、学習初期に得られた経験はあまり有用ではなく、結果として学習が非常に遅いという問題が指摘されています。このデータ収集の効率の悪さが深層強化学習を実ロボットの制御に適用する際の問題となっています。一方で、我々はアルゴリズムや状態表現の異なる複数の学習器を同時に学習できる並列学習法CLISを開発してきました。CLISでは制御則は線形のニューラルネットを用いていましたが、学習の進捗に応じて適切な状態表現を持つ学習器を自律的に選択し、有望なデータを効率よく収集できます。これにより、性能はあまり良くない単純な学習器が収集したデータを複雑な学習器の学習に用いることで、単に複雑な学習器だけを用いるよりも学習が高速化できることを示しました。本研究では、深層強化学習とCLISを統合した並列深層強化学習を開発し、深層強化学習のデータ収集効率を改善します。そして、現実的な時間で学習できるロボット学習のための手法を提案します。