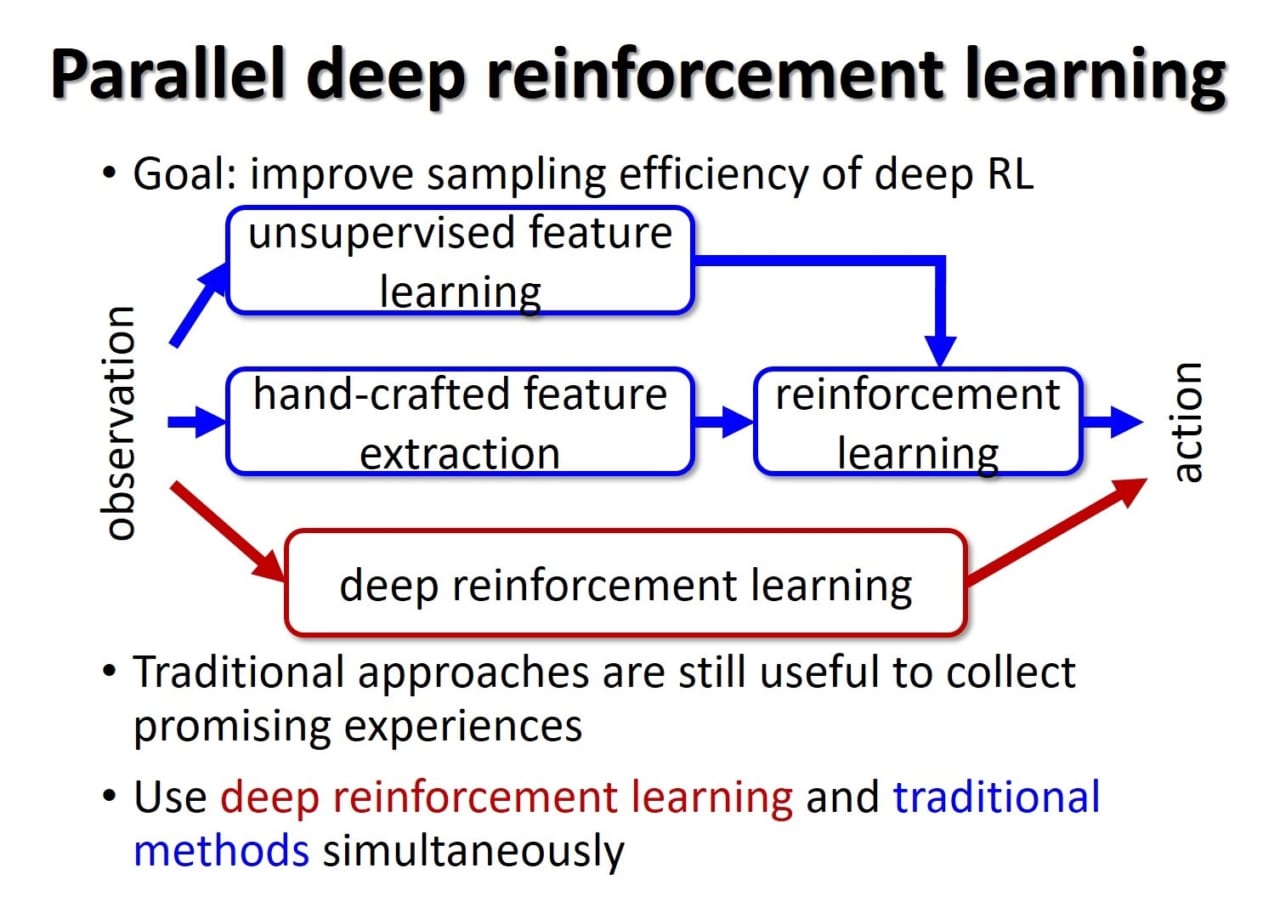
A02Parallel deep reinforcement learning
Google DeepMind showed the first widely remarkable success for Deep Reinforcement Learning (DRL) that can autonomously learn highly advanced control policies such as playing video games to the same extent as human experts and winning experts in Go. However, its learning is hopelessly slow since experiences are collected by a poor policy that is implemented by a randomly initialized deep neural network. This is one of bottlenecks to apply DRL into real robot control tasks. Meanwhile, we have proposed Cooperative, Competitive, and Concurrent Learning with Importance Sampling (CLIS) that trains multiple learning modules with different state representation and algorithms. Although we assumed that feature vectors in learning modules are designed manually, CLIS selects an appropriate learning algorithm with an appropriate representation according to the learning progress. We showed that CLIS improved the sampling efficiency of the learning module with complicated representation because those with simple representation quickly gather promising training data in the early stage for optimizing complicated modules. The goal of the project is to propose Parallel Deep Reinforcement Learning that combines DRL and CLIS in order to improve sampling efficiency of DRL and develop practical algorithms applicable to real robot control.