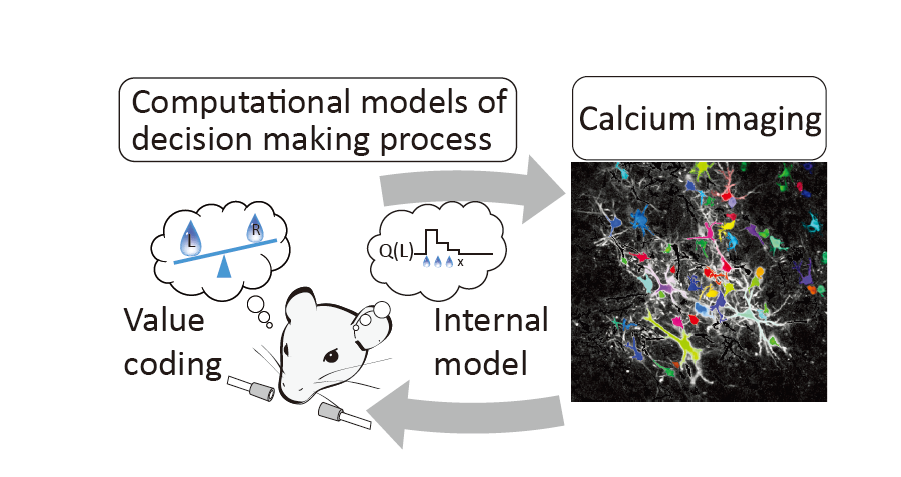
A01意思決定過程と内部モデルの相互作用
異なる場所や環境では、異なる行動規則を学ぶ必要があります。しかし、まったく新奇な環境におかれた時、どのようにして私たちは適切な行動を選択できるようになるのでしょうか。強化学習の理論に従えば、2つの主要な方法、モデルフリーとモデルベースの方法があります。新奇の環境に置かれた動物は、環境に対する知識を持たないため、報酬期待(行動価値関数)を報酬期待誤差から直接学習するモデルフリーの強化学習を行います。一方で、環境の内部モデルを学習した個体は、行動とその結果起こる状態変化の予測を用いて行動価値関数を構築し、適切な行動をモデルベースで選択することが可能になります。
移動や時間の経過によって環境が変化する実世界では、脳にとって、そして人工知能にとっても、モデルフリーの行動選択と、モデルベースの行動選択の回路を適切に組み合わせる必要があります。我々は先の公募研究において、有限の報酬(エサ)といった物理的制約であれば、げっ歯類が獲得しうる事を明らかにしました。本研究では、内部モデルを学習するマウスの前頭皮質を 2光子カルシウムイメージング法によって観察し、内部モデルを用いて意思決定を行う神経メカニズムを明らかにします。