Public Channels
- # discussions
- # keynote_tenenbaum
- # s1_lecun
- # s1_matsuo
- # s1_precup
- # s1_silver
- # s1_sugiyama
- # s2_fiete
- # s2_friston
- # s2_nagai
- # s2_sahani
- # s2_taniguchi
- # s3_botvinick
- # s3_kanai
- # s3_langdon
- # s3_nakahara
- # s3_wang
- # s4_dicarlo
- # s4_kamitani
- # s4_moran
- # s4_sejnowski
- # s4_takahashi
- # s5_churhland
- # s5_doya
- # s5_ema
- # s5_kitano
- # s5_russell
Private Channels
Direct Messages
Group Direct Messages

This is a discussion channel for "Reconstructing Visual and Subjective Experience from the Brain" by Prof. Kamitani (Kyoto University & ATR) A link to the talk is the following. Please do not share the link to anyone outside of this slack workspace. Access Passcode can be found at the announcement channel.
URL:https://vimeo.com/471283935 (23 minutes)

Thank you for the wonderful talk. I would like to ask you, if you have tested how much higher performance your DNN methods produce compared to the approaches that Jack L. Gallant used roughly a decade ago for reconstructing images and movies from fMRI data.

*Thread Reply:* Thanks for your comment. Gallant group's work is not reconstruction (in my view, reconstruction should cover arbitrary images in the whole image space) but a matching to a most likely stimulus among predefined candidate set based on the encoding model's prediction. They sometimes average the top most likely stimuli, which makes the image blurred and look like a synthesized image.
*Thread Reply:* You are absolutely right that he used dictionaries of images and movies for "reconstruction" too. But he also tried a different approach before that too. e.g. there is a nature paper called "Identifying natural images from human brain activity" (see the doi above). Well, it is over a decade ago when he explained me what he was doing at that time... :-)



https://www.nature.com/articles/ncomms15037
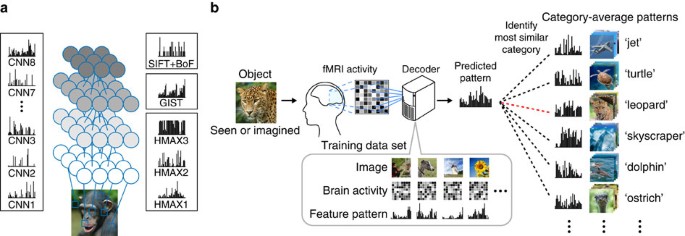
https://www.frontiersin.org/articles/10.3389/fncom.2017.00004/full
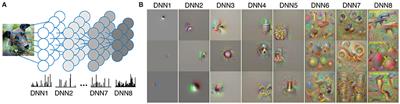
https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1006633
https://www.biorxiv.org/content/10.1101/2020.07.22.216713v1
https://www.youtube.com/watch?v=jsp1KaM-avU&feature=youtu.be
