A02Deep Parallel Reinforcement Learning with Model-Free and Model-Based Methods
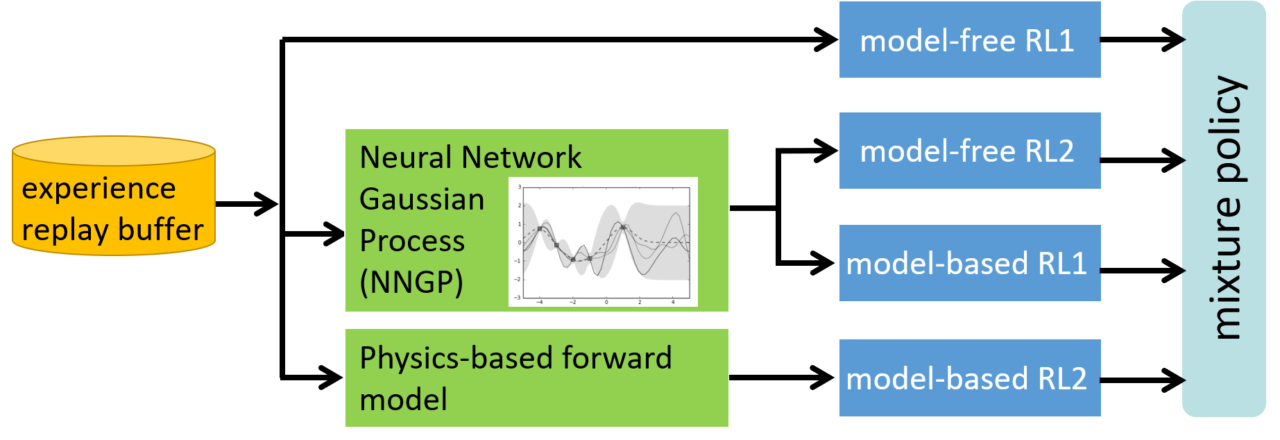
Reinforcement learning, which is a computational model of behavior learning, can be divided into model-free methods that do not require environmental models and model-based methods that estimate and use them explicitly. Intuitive/habitual human decision-making corresponds to model-free reinforcement learning while predictive/planned decision-making corresponds to model-based reinforcement learning. In humans and animals, model-free and model-based modules work cooperatively and competitively according to the situation. We have developed CRAIL, which is a cooperative and competitive learning system for multiple model-free reinforcement and self-imitation learning, but CRAIL does not consider model-based methods. This project extends CRAIL and develops a parallel deep reinforcement learning method that dynamically switches multiple reinforcement learning modules with different properties considering model-based and model-free reinforcement learning to improve learning efficiency.